
Hi,
Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements.
regards.
Usman

Hi,
Hmm. I thought this was fixed and that you said at the end that the performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti usman.bhatti@gmail.com wrote:
Hi,
Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
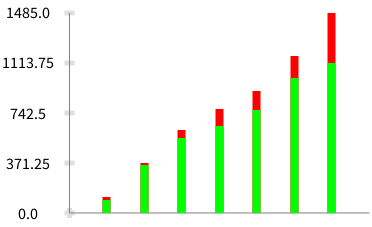
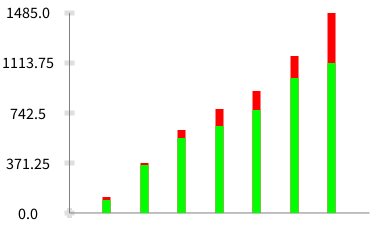
Here is a script that shows the factor of 2 in time taken for parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume).
|rule wrongBranches| [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into: [:acc :each | acc / each asCharacter asParser]. rule := PPDelegateParser new. rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). rule parse: (String streamContents: [ :s | 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun
Below are the graphs that were generated when varying the string length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP.
[image: Inline image 2]
Data values and graph generated by the script in the attached file.
regards.
usman
On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com wrote:
Hi,
Hmm. I thought this was fixed and that you said at the end that the performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti usman.bhatti@gmail.com wrote:
Hi,
Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
{kind=link}

Usman, this is a really cool bug report !
On 30 Jan 2015, at 16:36, Usman Bhatti usman.bhatti@gmail.com wrote:
Here is a script that shows the factor of 2 in time taken for parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume).
|rule wrongBranches| [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into: [:acc :each | acc / each asCharacter asParser]. rule := PPDelegateParser new. rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). rule parse: (String streamContents: [ :s | 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun
Below are the graphs that were generated when varying the string length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP.
<graph.png>
Data values and graph generated by the script in the attached file.
regards.
usman
On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com wrote: Hi,
Hmm. I thought this was fixed and that you said at the end that the performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti usman.bhatti@gmail.com wrote: Hi,
Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
<script-graph.txt>_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe sven@stfx.eu wrote:
Usman, this is a really cool bug report !
Thanks :)
On 30 Jan 2015, at 16:36, Usman Bhatti usman.bhatti@gmail.com wrote:
Here is a script that shows the factor of 2 in time taken for parsing.
The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume).
|rule wrongBranches| [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into:
[:acc :each | acc / each asCharacter asParser].
rule := PPDelegateParser new. rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). rule parse: (String streamContents: [ :s | 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun
Below are the graphs that were generated when varying the string length
provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP.
<graph.png>
Data values and graph generated by the script in the attached file.
regards.
usman
On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com
wrote:
Hi,
Hmm. I thought this was fixed and that you said at the end that the
performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x
performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti usman.bhatti@gmail.com
wrote:
Hi,
Since the work on the integration of PPContext in PetitParser, there is
significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be we
can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can provide
relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
<script-graph.txt>_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev

Hey all, thanks for the report, I will have a look at it asap.
Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" usman.bhatti@gmail.com wrote:
On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe sven@stfx.eu wrote:
Usman, this is a really cool bug report !
Thanks :)
On 30 Jan 2015, at 16:36, Usman Bhatti usman.bhatti@gmail.com wrote:
Here is a script that shows the factor of 2 in time taken for parsing.
The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume).
|rule wrongBranches| [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into:
[:acc :each | acc / each asCharacter asParser].
rule := PPDelegateParser new. rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). rule parse: (String streamContents: [ :s | 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun
Below are the graphs that were generated when varying the string length
provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP.
<graph.png>
Data values and graph generated by the script in the attached file.
regards.
usman
On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com
wrote:
Hi,
Hmm. I thought this was fixed and that you said at the end that the
performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x
performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti usman.bhatti@gmail.com
wrote:
Hi,
Since the work on the integration of PPContext in PetitParser, there is
significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be we
can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can provide
relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
<script-graph.txt>_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Hey all, Please note that a new version in of PetitParser (JanKurs-271) should improve performance roughly comparable to the original performance. On my computer, I got improvement from 3900ms to 1300ms.
Cheers, Jan
On 1 February 2015 at 22:55, Jan Kurš kurs.jan@gmail.com wrote:
Hey all, thanks for the report, I will have a look at it asap.
Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" usman.bhatti@gmail.com wrote:
On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe sven@stfx.eu wrote:
Usman, this is a really cool bug report !
Thanks :)
On 30 Jan 2015, at 16:36, Usman Bhatti usman.bhatti@gmail.com wrote:
Here is a script that shows the factor of 2 in time taken for parsing.
The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume).
|rule wrongBranches| [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into:
[:acc :each | acc / each asCharacter asParser].
rule := PPDelegateParser new. rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). rule parse: (String streamContents: [ :s | 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun
Below are the graphs that were generated when varying the string
length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP.
<graph.png>
Data values and graph generated by the script in the attached file.
regards.
usman
On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com
wrote:
Hi,
Hmm. I thought this was fixed and that you said at the end that the
performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x
performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti usman.bhatti@gmail.com
wrote:
Hi,
Since the work on the integration of PPContext in PetitParser, there
is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be
we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can provide
relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
<script-graph.txt>_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Great news.
@Usman: could you check?
Doru
On Fri, Feb 20, 2015 at 9:04 AM, Jan Kurš kurs.jan@gmail.com wrote:
Hey all, Please note that a new version in of PetitParser (JanKurs-271) should improve performance roughly comparable to the original performance. On my computer, I got improvement from 3900ms to 1300ms.
Cheers, Jan
On 1 February 2015 at 22:55, Jan Kurš kurs.jan@gmail.com wrote:
Hey all, thanks for the report, I will have a look at it asap.
Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" usman.bhatti@gmail.com wrote:
On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe sven@stfx.eu wrote:
Usman, this is a really cool bug report !
Thanks :)
On 30 Jan 2015, at 16:36, Usman Bhatti usman.bhatti@gmail.com
wrote:
Here is a script that shows the factor of 2 in time taken for
parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume).
|rule wrongBranches| [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into:
[:acc :each | acc / each asCharacter asParser].
rule := PPDelegateParser new. rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). rule parse: (String streamContents: [ :s | 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun
Below are the graphs that were generated when varying the string
length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP.
<graph.png>
Data values and graph generated by the script in the attached file.
regards.
usman
On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com
wrote:
Hi,
Hmm. I thought this was fixed and that you said at the end that the
performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x
performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti <
usman.bhatti@gmail.com> wrote:
Hi,
Since the work on the integration of PPContext in PetitParser, there
is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be
we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can
provide relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
<script-graph.txt>_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
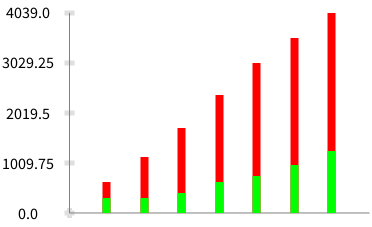
I executed the script that I shared earlier in this thread and I see a considerable performance improvement in the latest version of PP. The attached chart shows the comparison chart between PP v 1.51 (green) with the newer version (red). For shorter strings (i.e. to the left on x-axis), the execution time is almost comparable to the previous version of PetitParser that dates before changes introduced by Jan.
However, when I take the new version and parse the code source of larger code bases, the execution time still get a hit. For example, parsing 100K lines takes almost twice longer. The increase is exponential with even larger ones. That is consistent with results we see in the graph (the larger the chain to be parsed i.e. going from left to right in the x-axis, the higher the performance penalty). Meaning I still prefer the older version.
What will be good is to prepare some benches with Java Parser in PP, as it is open source, and a set of programs (e.g. ArguUML) that can serve as a standard to test execution time for PP that we can run as a jenkins service.
[image: Inline image 1]
regards.
On Fri, Feb 20, 2015 at 9:09 AM, Tudor Girba tudor@tudorgirba.com wrote:
Great news.
@Usman: could you check?
Doru
On Fri, Feb 20, 2015 at 9:04 AM, Jan Kurš kurs.jan@gmail.com wrote:
Hey all, Please note that a new version in of PetitParser (JanKurs-271) should improve performance roughly comparable to the original performance. On my computer, I got improvement from 3900ms to 1300ms.
Cheers, Jan
On 1 February 2015 at 22:55, Jan Kurš kurs.jan@gmail.com wrote:
Hey all, thanks for the report, I will have a look at it asap.
Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" usman.bhatti@gmail.com wrote:
On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe sven@stfx.eu wrote:
Usman, this is a really cool bug report !
Thanks :)
On 30 Jan 2015, at 16:36, Usman Bhatti usman.bhatti@gmail.com
wrote:
Here is a script that shows the factor of 2 in time taken for
parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume).
|rule wrongBranches| [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into:
[:acc :each | acc / each asCharacter asParser].
rule := PPDelegateParser new. rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). rule parse: (String streamContents: [ :s | 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun
Below are the graphs that were generated when varying the string
length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP.
<graph.png>
Data values and graph generated by the script in the attached file.
regards.
usman
On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com
wrote:
Hi,
Hmm. I thought this was fixed and that you said at the end that the
performance penalty is no longer a factor of 2.
Do you have a simple example for checking the simple case of 2x
performance loss?
Doru
On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti <
usman.bhatti@gmail.com> wrote:
Hi,
Since the work on the integration of PPContext in PetitParser, there
is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h.
I have not been able to reproduce my case on simple grammars. May be
we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML).
Currently, I circumvent this issue by using PP v1.51 but I can
provide relevant feedback and run benches on any improvements.
regards.
Usman
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
<script-graph.txt>_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
{kind=link}
Hey,
I was not aware about some exponential element in the overall complexity, it is strange and I will investigate it. Thank you Usman, for pointing this out.
In general, it is hard to add features into the PetitParser and preserve performance. Therefore, we work on a tool, that will take PetitParser, analyze it and generates faster parser. The idea is to use PetitParser while developing the grammar and than generate a fast parser for "real" use. We hope we will be present the tool during the next ESUG.
Cheers, Jan
On 20 February 2015 at 17:47, Usman Bhatti usman.bhatti@gmail.com wrote:
I executed the script that I shared earlier in this thread and I see a considerable performance improvement in the latest version of PP. The attached chart shows the comparison chart between PP v 1.51 (green) with the newer version (red). For shorter strings (i.e. to the left on x-axis), the execution time is almost comparable to the previous version of PetitParser that dates before changes introduced by Jan.
However, when I take the new version and parse the code source of larger code bases, the execution time still get a hit. For example, parsing 100K lines takes almost twice longer. The increase is exponential with even larger ones. That is consistent with results we see in the graph (the larger the chain to be parsed i.e. going from left to right in the x-axis, the higher the performance penalty). Meaning I still prefer the older version.
What will be good is to prepare some benches with Java Parser in PP, as it is open source, and a set of programs (e.g. ArguUML) that can serve as a standard to test execution time for PP that we can run as a jenkins service.
[image: Inline image 1]
regards.
On Fri, Feb 20, 2015 at 9:09 AM, Tudor Girba tudor@tudorgirba.com wrote:
Great news.
@Usman: could you check?
Doru
On Fri, Feb 20, 2015 at 9:04 AM, Jan Kurš kurs.jan@gmail.com wrote:
Hey all, Please note that a new version in of PetitParser (JanKurs-271) should improve performance roughly comparable to the original performance. On my computer, I got improvement from 3900ms to 1300ms.
Cheers, Jan
On 1 February 2015 at 22:55, Jan Kurš kurs.jan@gmail.com wrote:
Hey all, thanks for the report, I will have a look at it asap.
Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" usman.bhatti@gmail.com wrote:
On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe sven@stfx.eu wrote:
Usman, this is a really cool bug report !
Thanks :)
> On 30 Jan 2015, at 16:36, Usman Bhatti usman.bhatti@gmail.com wrote: > > Here is a script that shows the factor of 2 in time taken for parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume). > > |rule wrongBranches| > [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into: [:acc :each | acc / each asCharacter asParser]. > rule := PPDelegateParser new. > rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). > rule parse: (String streamContents: [ :s | > 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun > > > Below are the graphs that were generated when varying the string length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP. > > <graph.png> > > Data values and graph generated by the script in the attached file. > > regards. > > usman > > On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba tudor@tudorgirba.com wrote: > Hi, > > Hmm. I thought this was fixed and that you said at the end that the performance penalty is no longer a factor of 2. > > Do you have a simple example for checking the simple case of 2x performance loss? > > Doru > > > On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti < usman.bhatti@gmail.com> wrote: > Hi, > > Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h. > > I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML). > > Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements. > > regards. > > Usman > > _______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch > https://www.iam.unibe.ch/mailman/listinfo/moose-dev > > > > > -- > www.tudorgirba.com > > "Every thing has its own flow" > > _______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch > https://www.iam.unibe.ch/mailman/listinfo/moose-dev > > > <script-graph.txt>_______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch > https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
-- www.tudorgirba.com
"Every thing has its own flow"
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
{kind=link}

Le 21/02/2015 11:14, Jan Kurš a écrit :
Hey,
I was not aware about some exponential element in the overall complexity, it is strange and I will investigate it. Thank you Usman, for pointing this out.
In general, it is hard to add features into the PetitParser and preserve performance. Therefore, we work on a tool, that will take PetitParser, analyze it and generates faster parser. The idea is to use PetitParser while developing the grammar and than generate a fast parser for "real" use. We hope we will be present the tool during the next ESUG.
I certainly be interested with what you come up with. From profiling PetitParser, it seems there is at least one low-hanging fruit in term of performance.
And thanks too Usman, for pointing out long source code files may (or do) show diverging asymptotic behaviors. And real life use for most programming languages are very long files :(
Thierry
Cheers, Jan
On 20 February 2015 at 17:47, Usman Bhatti <usman.bhatti@gmail.com mailto:usman.bhatti@gmail.com> wrote:
I executed the script that I shared earlier in this thread and I see a considerable performance improvement in the latest version of PP. The attached chart shows the comparison chart between PP v 1.51 (green) with the newer version (red). For shorter strings (i.e. to the left on x-axis), the execution time is almost comparable to the previous version of PetitParser that dates before changes introduced by Jan. However, when I take the new version and parse the code source of larger code bases, the execution time still get a hit. For example, parsing 100K lines takes almost twice longer. The increase is exponential with even larger ones. That is consistent with results we see in the graph (the larger the chain to be parsed i.e. going from left to right in the x-axis, the higher the performance penalty). Meaning I still prefer the older version. What will be good is to prepare some benches with Java Parser in PP, as it is open source, and a set of programs (e.g. ArguUML) that can serve as a standard to test execution time for PP that we can run as a jenkins service. Inline image 1 regards. On Fri, Feb 20, 2015 at 9:09 AM, Tudor Girba <tudor@tudorgirba.com <mailto:tudor@tudorgirba.com>> wrote: Great news. @Usman: could you check? Doru On Fri, Feb 20, 2015 at 9:04 AM, Jan Kurš <kurs.jan@gmail.com <mailto:kurs.jan@gmail.com>> wrote: Hey all, Please note that a new version in of PetitParser (JanKurs-271) should improve performance roughly comparable to the original performance. On my computer, I got improvement from 3900ms to 1300ms. Cheers, Jan On 1 February 2015 at 22:55, Jan Kurš <kurs.jan@gmail.com <mailto:kurs.jan@gmail.com>> wrote: Hey all, thanks for the report, I will have a look at it asap. Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" <usman.bhatti@gmail.com <mailto:usman.bhatti@gmail.com>> wrote: On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe <sven@stfx.eu <mailto:sven@stfx.eu>> wrote: Usman, this is a really cool bug report ! Thanks :) > On 30 Jan 2015, at 16:36, Usman Bhatti <usman.bhatti@gmail.com <mailto:usman.bhatti@gmail.com>> wrote: > > Here is a script that shows the factor of 2 in time taken for parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume). > > |rule wrongBranches| > [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into: [:acc :each | acc / each asCharacter asParser]. > rule := PPDelegateParser new. > rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). > rule parse: (String streamContents: [ :s | > 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun > > > Below are the graphs that were generated when varying the string length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP. > > <graph.png> > > Data values and graph generated by the script in the attached file. > > regards. > > usman > > On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba <tudor@tudorgirba.com <mailto:tudor@tudorgirba.com>> wrote: > Hi, > > Hmm. I thought this was fixed and that you said at the end that the performance penalty is no longer a factor of 2. > > Do you have a simple example for checking the simple case of 2x performance loss? > > Doru > > > On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti <usman.bhatti@gmail.com <mailto:usman.bhatti@gmail.com>> wrote: > Hi, > > Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h. > > I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML). > > Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements. > > regards. > > Usman > > _______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> > https://www.iam.unibe.ch/mailman/listinfo/moose-dev > > > > > -- > www.tudorgirba.com <http://www.tudorgirba.com> > > "Every thing has its own flow" > > _______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> > https://www.iam.unibe.ch/mailman/listinfo/moose-dev > > > <script-graph.txt>_______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> > https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev -- www.tudorgirba.com <http://www.tudorgirba.com> "Every thing has its own flow" _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Hi,
On Sat, Feb 21, 2015 at 8:07 PM, Thierry Goubier thierry.goubier@gmail.com wrote:
Le 21/02/2015 11:14, Jan Kurš a écrit :
Hey,
I was not aware about some exponential element in the overall complexity, it is strange and I will investigate it. Thank you Usman, for pointing this out.
In general, it is hard to add features into the PetitParser and preserve performance. Therefore, we work on a tool, that will take PetitParser, analyze it and generates faster parser. The idea is to use PetitParser while developing the grammar and than generate a fast parser for "real" use. We hope we will be present the tool during the next ESUG.
I certainly be interested with what you come up with. From profiling PetitParser, it seems there is at least one low-hanging fruit in term of performance.
What is that log hanging fruit?
Doru
And thanks too Usman, for pointing out long source code files may (or do) show diverging asymptotic behaviors. And real life use for most programming languages are very long files :(
Thierry
Cheers, Jan
On 20 February 2015 at 17:47, Usman Bhatti <usman.bhatti@gmail.com mailto:usman.bhatti@gmail.com> wrote:
I executed the script that I shared earlier in this thread and I see a considerable performance improvement in the latest version of PP. The attached chart shows the comparison chart between PP v 1.51 (green) with the newer version (red). For shorter strings (i.e. to the left on x-axis), the execution time is almost comparable to the previous version of PetitParser that dates before changes introduced by Jan. However, when I take the new version and parse the code source of larger code bases, the execution time still get a hit. For example, parsing 100K lines takes almost twice longer. The increase is exponential with even larger ones. That is consistent with results we see in the graph (the larger the chain to be parsed i.e. going from left to right in the x-axis, the higher the performance penalty). Meaning I still prefer the older version. What will be good is to prepare some benches with Java Parser in PP, as it is open source, and a set of programs (e.g. ArguUML) that can serve as a standard to test execution time for PP that we can run as a jenkins service. Inline image 1 regards. On Fri, Feb 20, 2015 at 9:09 AM, Tudor Girba <tudor@tudorgirba.com <mailto:tudor@tudorgirba.com>> wrote: Great news. @Usman: could you check? Doru On Fri, Feb 20, 2015 at 9:04 AM, Jan Kurš <kurs.jan@gmail.com <mailto:kurs.jan@gmail.com>> wrote: Hey all, Please note that a new version in of PetitParser (JanKurs-271) should improve performance roughly comparable to the original performance. On my computer, I got improvement from 3900ms to 1300ms. Cheers, Jan On 1 February 2015 at 22:55, Jan Kurš <kurs.jan@gmail.com <mailto:kurs.jan@gmail.com>> wrote: Hey all, thanks for the report, I will have a look at it asap. Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" <usman.bhatti@gmail.com <mailto:usman.bhatti@gmail.com>> wrote: On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe <sven@stfx.eu <mailto:sven@stfx.eu>>wrote:
Usman, this is a really cool bug report ! Thanks :) > On 30 Jan 2015, at 16:36, Usman Bhatti <usman.bhatti@gmail.com mailto:usman.bhatti@gmail.com> wrote: > > Here is a script that shows the factor of 2 in time taken for parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume). > > |rule wrongBranches| > [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into: [:acc :each | acc / each asCharacter asParser]. > rule := PPDelegateParser new. > rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). > rule parse: (String streamContents: [ :s | > 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun > > > Below are the graphs that were generated when varying the string length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP. > > <graph.png> > > Data values and graph generated by the script in the attached file. > > regards. > > usman > > On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba <tudor@tudorgirba.com mailto:tudor@tudorgirba.com> wrote: > Hi, > > Hmm. I thought this was fixed and that you said at the end that the performance penalty is no longer a factor of 2. > > Do you have a simple example for checking the simple case of 2x performance loss? > > Doru > > > On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti <usman.bhatti@gmail.com mailto:usman.bhatti@gmail.com> wrote: > Hi, > > Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h. > > I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML). > > Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements. > > regards. > > Usman > > ______________________________ _________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch mailto:Moose-dev@iam.unibe.ch > https://www.iam.unibe.ch/ mailman/listinfo/moose-dev > > > > > -- > www.tudorgirba.com http://www.tudorgirba.com > > "Every thing has its own flow" > > ______________________________ _________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch mailto:Moose-dev@iam.unibe.ch > https://www.iam.unibe.ch/ mailman/listinfo/moose-dev > > > <script-graph.txt>____________ ___________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch mailto:Moose-dev@iam.unibe.ch > https://www.iam.unibe.ch/ mailman/listinfo/moose-dev
_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev
_______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.chhttps://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev -- www.tudorgirba.com <http://www.tudorgirba.com> "Every thing has its own flow" _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Hi Doru,
the low hanging fruit is the time needed to create a PP parser (time for new).
I profiled PPSmalltalkParser over a bench used by Lucas Renggli a few years ago, and PPSmalltalkParser spends half the time in "new" (and it is a lot slower than it used to be).
Thierry
Le 21/02/2015 21:13, Tudor Girba a écrit :
Hi,
On Sat, Feb 21, 2015 at 8:07 PM, Thierry Goubier <thierry.goubier@gmail.com mailto:thierry.goubier@gmail.com> wrote:
Le 21/02/2015 11:14, Jan Kurš a écrit : Hey, I was not aware about some exponential element in the overall complexity, it is strange and I will investigate it. Thank you Usman, for pointing this out. In general, it is hard to add features into the PetitParser and preserve performance. Therefore, we work on a tool, that will take PetitParser, analyze it and generates faster parser. The idea is to use PetitParser while developing the grammar and than generate a fast parser for "real" use. We hope we will be present the tool during the next ESUG. I certainly be interested with what you come up with. From profiling PetitParser, it seems there is at least one low-hanging fruit in term of performance.What is that log hanging fruit?
Doru
Hi,
On Sat, Feb 21, 2015 at 11:03 PM, Thierry Goubier <thierry.goubier@gmail.com
wrote:
Hi Doru,
the low hanging fruit is the time needed to create a PP parser (time for new).
I still do not see the low hanging fruit. Do you have a concrete idea of how to make it faster?
I profiled PPSmalltalkParser over a bench used by Lucas Renggli a few years ago, and PPSmalltalkParser spends half the time in "new" (and it is a lot slower than it used to be).
What does "a lot slower" mean?
Doru
Thierry
Le 21/02/2015 21:13, Tudor Girba a écrit :
Hi,
On Sat, Feb 21, 2015 at 8:07 PM, Thierry Goubier <thierry.goubier@gmail.com mailto:thierry.goubier@gmail.com> wrote:
Le 21/02/2015 11:14, Jan Kurš a écrit : Hey, I was not aware about some exponential element in the overall complexity, it is strange and I will investigate it. Thank you Usman, for pointing this out. In general, it is hard to add features into the PetitParser and preserve performance. Therefore, we work on a tool, that will take PetitParser, analyze it and generates faster parser. The idea is to use PetitParser while developing the grammar and than generate a fast parser for "real" use. We hope we will be present the tool during the next ESUG. I certainly be interested with what you come up with. From profiling PetitParser, it seems there is at least one low-hanging fruit in term of performance.What is that log hanging fruit?
Doru
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Le 21/02/2015 23:18, Tudor Girba a écrit :
Hi,
On Sat, Feb 21, 2015 at 11:03 PM, Thierry Goubier <thierry.goubier@gmail.com mailto:thierry.goubier@gmail.com> wrote:
Hi Doru, the low hanging fruit is the time needed to create a PP parser (time for new).I still do not see the low hanging fruit. Do you have a concrete idea of how to make it faster?
Look at that instantiation code, cache the result. - Make a copy when you instantiate. - Recreate / recompute if you execute a method extending the parser on the resulting object. - Have a copy parser method which cleanly creates a new instance.
(i.e. summarized as: new should memoize and make a copy of the memoized version)
Or look into reflection for making some methods trigger code generation, as if parser combinators were written in pragmas :)
I profiled PPSmalltalkParser over a bench used by Lucas Renggli a few years ago, and PPSmalltalkParser spends half the time in "new" (and it is a lot slower than it used to be).What does "a lot slower" mean?
3 times slower in Pharo 4.
And this benchmark does not show any effect linked to long files; it's only a list of fairly short methods (all Object and Morph methods).
Thierry
Hi,
On Sat, Feb 21, 2015 at 11:46 PM, Thierry Goubier <thierry.goubier@gmail.com
wrote:
Le 21/02/2015 23:18, Tudor Girba a écrit :
Hi,
On Sat, Feb 21, 2015 at 11:03 PM, Thierry Goubier <thierry.goubier@gmail.com mailto:thierry.goubier@gmail.com> wrote:
Hi Doru, the low hanging fruit is the time needed to create a PP parser (time for new).I still do not see the low hanging fruit. Do you have a concrete idea of how to make it faster?
Look at that instantiation code, cache the result.
- Make a copy when you instantiate.
- Recreate / recompute if you execute a method extending the parser on the
resulting object.
- Have a copy parser method which cleanly creates a new instance.
(i.e. summarized as: new should memoize and make a copy of the memoized version)
This would go against the understood meaning of new which should return a new instance, not a cached one.
Or look into reflection for making some methods trigger code generation, as
if parser combinators were written in pragmas :)
I do not understand.
I profiled PPSmalltalkParser over a bench used by Lucas Renggli a few years ago, and PPSmalltalkParser spends half the time in "new" (and it is a lot slower than it used to be).What does "a lot slower" mean?
3 times slower in Pharo 4.
And this benchmark does not show any effect linked to long files; it's only
a list of fairly short methods (all Object and Morph methods).
3 times slower comparing what to what? :) Is this the benchmark comparing a hand-written parser with the PPSmalltalkParser? If yes, where can we see it the code? If the benchmark is calling new multiple times, it is not particularly relevant.
Cheers, Doru
Le 22/02/2015 11:32, Tudor Girba a écrit :
Hi,
On Sat, Feb 21, 2015 at 11:46 PM, Thierry Goubier <thierry.goubier@gmail.com mailto:thierry.goubier@gmail.com> wrote:
Le 21/02/2015 23:18, Tudor Girba a écrit : Hi, On Sat, Feb 21, 2015 at 11:03 PM, Thierry Goubier <thierry.goubier@gmail.com <mailto:thierry.goubier@gmail.com> <mailto:thierry.goubier@gmail.__com <mailto:thierry.goubier@gmail.com>>> wrote: Hi Doru, the low hanging fruit is the time needed to create a PP parser (time for new). I still do not see the low hanging fruit. Do you have a concrete idea of how to make it faster? Look at that instantiation code, cache the result. - Make a copy when you instantiate. - Recreate / recompute if you execute a method extending the parser on the resulting object. - Have a copy parser method which cleanly creates a new instance. (i.e. summarized as: new should memoize and make a copy of the memoized version)This would go against the understood meaning of new which should return a new instance, not a cached one.
new would clone a pre-existing instance. Just the Self way.
Ok, it's cheating a bit, but it could work (hypothesis: making a copy of a PP parser instance isn't expensive)
Or look into reflection for making some methods trigger code generation, as if parser combinators were written in pragmas :)I do not understand.
Well, one of the way to look at PetitParser is that it provides an object-oriented API to the creation of grammars. So, I could very well write an SmaCC layer which would allow a PetitParser parser design to generate a Grammar (and maybe keep some of the semantic actions, but probably not all).
This would be some of the same ideas.
When one writes a method like:
array ^ ${ asParser smalltalkToken , (expression delimitedBy: periodToken) optional , $} asParser smalltalkToken
One in truth describe two things: a declarative way of writing a grammar production which in SmaCC would be :
array: "{" (expression ".")* "}" ;
(approximately)
And a resolution (i.e. the code to execute the parse) as well.
One of the idea would be to execute and generate the declarative part of the method above, so that, when you instantiate the parser, not much is left to do.
3 times slower in Pharo 4. And this benchmark does not show any effect linked to long files; it's only a list of fairly short methods (all Object and Morph methods).3 times slower comparing what to what? :) Is this the benchmark comparing a hand-written parser with the PPSmalltalkParser? If yes, where can we see it the code? If the benchmark is calling new multiple times, it is not particularly relevant.
I said PetitParser is slower than it used to be (3 times slower).
I used the relative speed of that benchmark to estimate. Ranking is:
RBParser: 400ms SmaCC StParser: 2100ms PPSmalltalkParser: 9000ms where I expected it to be, from Lukas numbers, at 3000ms or less. Hence 3 times slower than it used to be (and 22 times slower than the hand written parser)
I have a fair idea of where SmaCC is slow, and its totally not where I expected it. But as it has no asymptotic performance problem, it works well as a compiler front-end for C, for example.
Bench is simply to run:
ObjectAndMorph do: [ :each | PPSmalltalkParser parse: each ]
(replace with RBParser>>parseMethod:, StParser>>parseMethod: to compare)
With, somewhere, in a global, this:
ObjectAndMorph := Object allMethods , Morph allMethods collect: #sourceCode
to avoid having the sourceCode polluting the profile.
(Note: run times on Spur don't differ much, so no gain there to expect).
Thierry

So the easy solution in ‘production use’ would be to create the parser once and then keep hanging on to it? I would not say that this is really a PetitParser issue, but more how the parser is used.
On Feb 21, 2015, at 19:03, Thierry Goubier thierry.goubier@gmail.com wrote:
Hi Doru,
the low hanging fruit is the time needed to create a PP parser (time for new).
I profiled PPSmalltalkParser over a bench used by Lucas Renggli a few years ago, and PPSmalltalkParser spends half the time in "new" (and it is a lot slower than it used to be).
Thierry
---> Save our in-boxes! http://emailcharter.org <---
Johan Fabry - http://pleiad.cl/~jfabry PLEIAD lab - Computer Science Department (DCC) - University of Chile
Le 21/02/2015 23:24, Johan Fabry a écrit :
So the easy solution in ‘production use’ would be to create the parser once and then keep hanging on to it? I would not say that this is really a PetitParser issue, but more how the parser is used.
All other Smalltalk parsers are instantiated as many times as the PetitParser one in this benchmark, and their instanciation time is around 0 ms.
But, yes, I would think that one of the solution would be a pre-instantiation of a PetitParser, and a final instantiation to create an instance.
In a way, one could imagine writing SmaCC parsers in the same way that PetitParser parsers are written... pre-instantiation being the part where SmaCC generates and compile its parsers.
In this benchmark, this would cut parsing time by 2.
Thierry
Yes. This is also the reason why PPCompositeParser caches the internal parser objects.
Cheers, Doru
On Sat, Feb 21, 2015 at 11:24 PM, Johan Fabry jfabry@dcc.uchile.cl wrote:
So the easy solution in ‘production use’ would be to create the parser once and then keep hanging on to it? I would not say that this is really a PetitParser issue, but more how the parser is used.
On Feb 21, 2015, at 19:03, Thierry Goubier thierry.goubier@gmail.com
wrote:
Hi Doru,
the low hanging fruit is the time needed to create a PP parser (time for
new).
I profiled PPSmalltalkParser over a bench used by Lucas Renggli a few
years ago, and PPSmalltalkParser spends half the time in "new" (and it is a lot slower than it used to be).
Thierry
---> Save our in-boxes! http://emailcharter.org <---
Johan Fabry - http://pleiad.cl/~jfabry PLEIAD lab - Computer Science Department (DCC) - University of Chile
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Le 21/02/2015 22:04, stepharo a écrit :
And thanks too Usman, for pointing out long source code files may (or do) show diverging asymptotic behaviors. And real life use for most programming languages are very long files :(
Like one method with 15 pages ? :)
Only 15 pages? I believe SmaCC can generate longuer methods than that :)
Thierry

Hey,
I was not aware about some exponential element in the overall complexity, it is strange and I will investigate it. Thank you Usman, for pointing this out.
In general, it is hard to add features into the PetitParser and preserve performance.
I imagine. May be one idea would be also to have different flavors of PP.
Therefore, we work on a tool, that will take PetitParser, analyze it and generates faster parser. The idea is to use PetitParser while developing the grammar and than generate a fast parser for "real" use. We hope we will be present the tool during the next ESUG.
That could be gorgeous. If Synectique takes off for real (which I really hope), I'm sure that Synectique will think hard about you as a synectiquer :).
Stef
Cheers, Jan
On 20 February 2015 at 17:47, Usman Bhatti <usman.bhatti@gmail.com mailto:usman.bhatti@gmail.com> wrote:
I executed the script that I shared earlier in this thread and I see a considerable performance improvement in the latest version of PP. The attached chart shows the comparison chart between PP v 1.51 (green) with the newer version (red). For shorter strings (i.e. to the left on x-axis), the execution time is almost comparable to the previous version of PetitParser that dates before changes introduced by Jan. However, when I take the new version and parse the code source of larger code bases, the execution time still get a hit. For example, parsing 100K lines takes almost twice longer. The increase is exponential with even larger ones. That is consistent with results we see in the graph (the larger the chain to be parsed i.e. going from left to right in the x-axis, the higher the performance penalty). Meaning I still prefer the older version. What will be good is to prepare some benches with Java Parser in PP, as it is open source, and a set of programs (e.g. ArguUML) that can serve as a standard to test execution time for PP that we can run as a jenkins service. Inline image 1 regards. On Fri, Feb 20, 2015 at 9:09 AM, Tudor Girba <tudor@tudorgirba.com <mailto:tudor@tudorgirba.com>> wrote: Great news. @Usman: could you check? Doru On Fri, Feb 20, 2015 at 9:04 AM, Jan Kurš <kurs.jan@gmail.com <mailto:kurs.jan@gmail.com>> wrote: Hey all, Please note that a new version in of PetitParser (JanKurs-271) should improve performance roughly comparable to the original performance. On my computer, I got improvement from 3900ms to 1300ms. Cheers, Jan On 1 February 2015 at 22:55, Jan Kurš <kurs.jan@gmail.com <mailto:kurs.jan@gmail.com>> wrote: Hey all, thanks for the report, I will have a look at it asap. Cheers Jan On 1 Feb 2015 20:55, "Usman Bhatti" <usman.bhatti@gmail.com <mailto:usman.bhatti@gmail.com>> wrote: On Fri, Jan 30, 2015 at 9:36 PM, Sven Van Caekenberghe <sven@stfx.eu <mailto:sven@stfx.eu>> wrote: Usman, this is a really cool bug report ! Thanks :) > On 30 Jan 2015, at 16:36, Usman Bhatti <usman.bhatti@gmail.com <mailto:usman.bhatti@gmail.com>> wrote: > > Here is a script that shows the factor of 2 in time taken for parsing. The idea of the script is to introduce several wrong branches before hitting the correct one (originally proposed by Guillaume). > > |rule wrongBranches| > [wrongBranches := (25 to: 45) inject: 24 asCharacter asParser into: [:acc :each | acc / each asCharacter asParser]. > rule := PPDelegateParser new. > rule setParser: $a asParser / ((wrongBranches / $. asParser), rule). > rule parse: (String streamContents: [ :s | > 30000 timesRepeat: [s nextPut: $.]. s nextPut: $a ])] timeToRun > > > Below are the graphs that were generated when varying the string length provided to the above parser description. Green part shows the time taken by the older version and the red part with the latest PP. > > <graph.png> > > Data values and graph generated by the script in the attached file. > > regards. > > usman > > On Fri, Jan 30, 2015 at 1:30 PM, Tudor Girba <tudor@tudorgirba.com <mailto:tudor@tudorgirba.com>> wrote: > Hi, > > Hmm. I thought this was fixed and that you said at the end that the performance penalty is no longer a factor of 2. > > Do you have a simple example for checking the simple case of 2x performance loss? > > Doru > > > On Fri, Jan 30, 2015 at 12:28 PM, Usman Bhatti <usman.bhatti@gmail.com <mailto:usman.bhatti@gmail.com>> wrote: > Hi, > > Since the work on the integration of PPContext in PetitParser, there is significant performance degradation. I have already mentioned that on simple grammar the factor is about 2. But on complex grammar (for example, our proprietary parser for 4D language ), we have seen that degradation is goes well beyond this factor. So, for example, for 800K lines that we parse in under 10 minutes without PPContext work, with the latest version it goes beyond 2h. > > I have not been able to reproduce my case on simple grammars. May be we can have some benchmarks using open source parsers and large code bases (e.g. PP Java Parser on JHotDraw or ArgoUML). > > Currently, I circumvent this issue by using PP v1.51 but I can provide relevant feedback and run benches on any improvements. > > regards. > > Usman > > _______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> > https://www.iam.unibe.ch/mailman/listinfo/moose-dev > > > > > -- > www.tudorgirba.com <http://www.tudorgirba.com> > > "Every thing has its own flow" > > _______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> > https://www.iam.unibe.ch/mailman/listinfo/moose-dev > > > <script-graph.txt>_______________________________________________ > Moose-dev mailing list > Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> > https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev -- www.tudorgirba.com <http://www.tudorgirba.com> "Every thing has its own flow" _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev _______________________________________________ Moose-dev mailing list Moose-dev@iam.unibe.ch <mailto:Moose-dev@iam.unibe.ch> https://www.iam.unibe.ch/mailman/listinfo/moose-dev
Moose-dev mailing list Moose-dev@iam.unibe.ch https://www.iam.unibe.ch/mailman/listinfo/moose-dev
{kind=link}
Therefore, we work on a tool, that will take PetitParser, analyze it and generates faster parser. The idea is to use PetitParser while developing the grammar and than generate a fast parser for "real" use. We hope we will be present the tool during the next ESUG.
Oh yes that would be extremely cool! I would love to have faster parsing for Live Robot Programming as it parses the program at every keystroke. Right now it’s not a real issue but as robot code will get bigger I imagine that it will become so …
---> Save our in-boxes! http://emailcharter.org <---
Johan Fabry - http://pleiad.cl/~jfabry PLEIAD lab - Computer Science Department (DCC) - University of Chile
-
 Jan Kurš
Jan Kurš -
 Johan Fabry
Johan Fabry -
 stepharo
stepharo -
 Sven Van Caekenberghe
Sven Van Caekenberghe -
 Thierry Goubier
Thierry Goubier -
 Tudor Girba
Tudor Girba -
 Usman Bhatti
Usman Bhatti